EDA notebook¶
![]()
This notebook contains the simple examples of EDA (exploratory data analysis) using ETNA library.
Table of Contents
[29]:
import warnings
warnings.filterwarnings("ignore")
1. Creating TSDataset¶
Let’s load and look at the dataset
[30]:
import pandas as pd
[31]:
classic_df = pd.read_csv("data/example_dataset.csv")
classic_df.head()
[31]:
| timestamp | segment | target | |
|---|---|---|---|
| 0 | 2019-01-01 | segment_a | 170 |
| 1 | 2019-01-02 | segment_a | 243 |
| 2 | 2019-01-03 | segment_a | 267 |
| 3 | 2019-01-04 | segment_a | 287 |
| 4 | 2019-01-05 | segment_a | 279 |
Our library works with the special data structure TSDataset. So, before starting the EDA, we need to convert the classical DataFrame to TSDataset.
[32]:
from etna.datasets.tsdataset import TSDataset
To do this, we initially need to convert the classical DataFrame to the special format
[33]:
df = TSDataset.to_dataset(classic_df)
df.head()
[33]:
| segment | segment_a | segment_b | segment_c | segment_d |
|---|---|---|---|---|
| feature | target | target | target | target |
| timestamp | ||||
| 2019-01-01 | 170 | 102 | 92 | 238 |
| 2019-01-02 | 243 | 123 | 107 | 358 |
| 2019-01-03 | 267 | 130 | 103 | 366 |
| 2019-01-04 | 287 | 138 | 103 | 385 |
| 2019-01-05 | 279 | 137 | 104 | 384 |
Now we can construct the TSDataset
[34]:
ts = TSDataset(df, freq="D")
ts.head(5)
[34]:
| segment | segment_a | segment_b | segment_c | segment_d |
|---|---|---|---|---|
| feature | target | target | target | target |
| timestamp | ||||
| 2019-01-01 | 170 | 102 | 92 | 238 |
| 2019-01-02 | 243 | 123 | 107 | 358 |
| 2019-01-03 | 267 | 130 | 103 | 366 |
| 2019-01-04 | 287 | 138 | 103 | 385 |
| 2019-01-05 | 279 | 137 | 104 | 384 |
TSDataset has its own implementations of describe and info methods that gives information about distinct time series.
[35]:
ts.describe()
[35]:
| start_timestamp | end_timestamp | length | num_missing | num_segments | num_exogs | num_regressors | num_known_future | freq | |
|---|---|---|---|---|---|---|---|---|---|
| segments | |||||||||
| segment_a | 2019-01-01 | 2019-11-30 | 334 | 0 | 4 | 0 | 0 | 0 | D |
| segment_b | 2019-01-01 | 2019-11-30 | 334 | 0 | 4 | 0 | 0 | 0 | D |
| segment_c | 2019-01-01 | 2019-11-30 | 334 | 0 | 4 | 0 | 0 | 0 | D |
| segment_d | 2019-01-01 | 2019-11-30 | 334 | 0 | 4 | 0 | 0 | 0 | D |
[36]:
ts.info()
<class 'etna.datasets.TSDataset'>
num_segments: 4
num_exogs: 0
num_regressors: 0
num_known_future: 0
freq: D
start_timestamp end_timestamp length num_missing
segments
segment_a 2019-01-01 2019-11-30 334 0
segment_b 2019-01-01 2019-11-30 334 0
segment_c 2019-01-01 2019-11-30 334 0
segment_d 2019-01-01 2019-11-30 334 0
2. Visualization¶
Our library provides a list of utilities for visual data exploration. So, having the dataset converted to TSDataset, now we can visualize it.
[37]:
from etna.analysis import (
cross_corr_plot,
distribution_plot,
acf_plot,
plot_correlation_matrix,
)
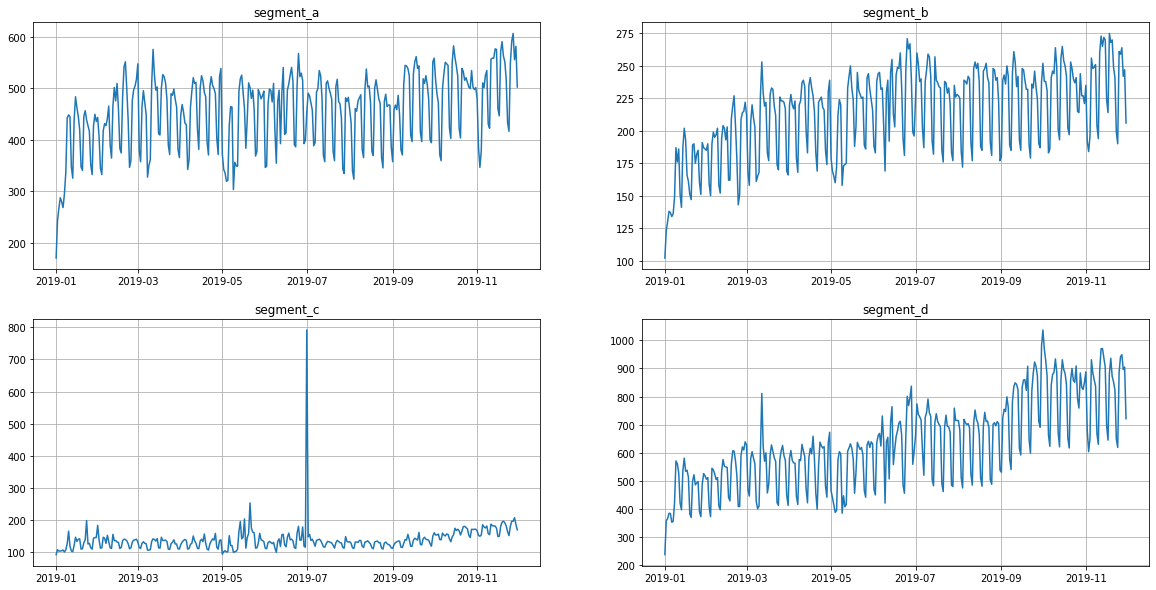
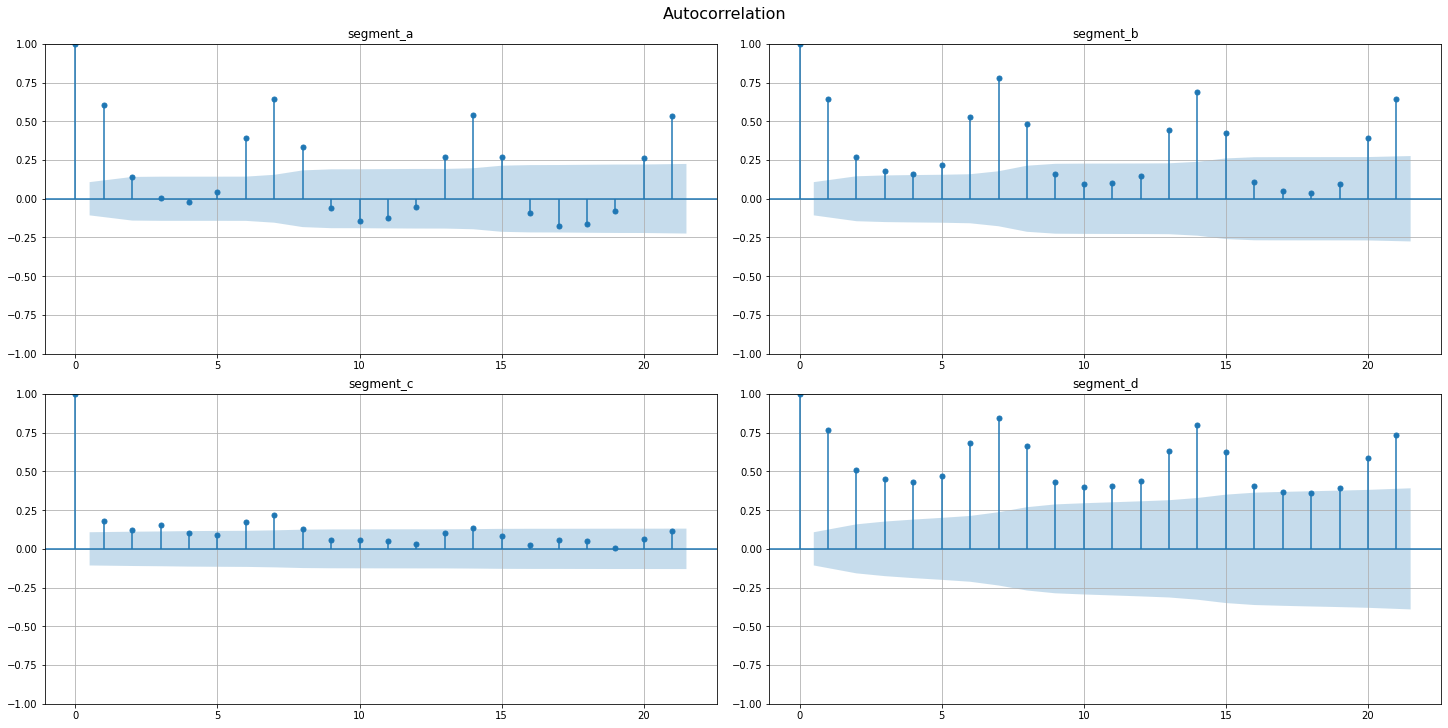
2.2 Autocorrelation & partial autocorrelation¶
Autocorrelation function(AFC) describes the direct relationship between an observation and its lag. The AFC plot can help to identify the extent of the lag in moving average models.
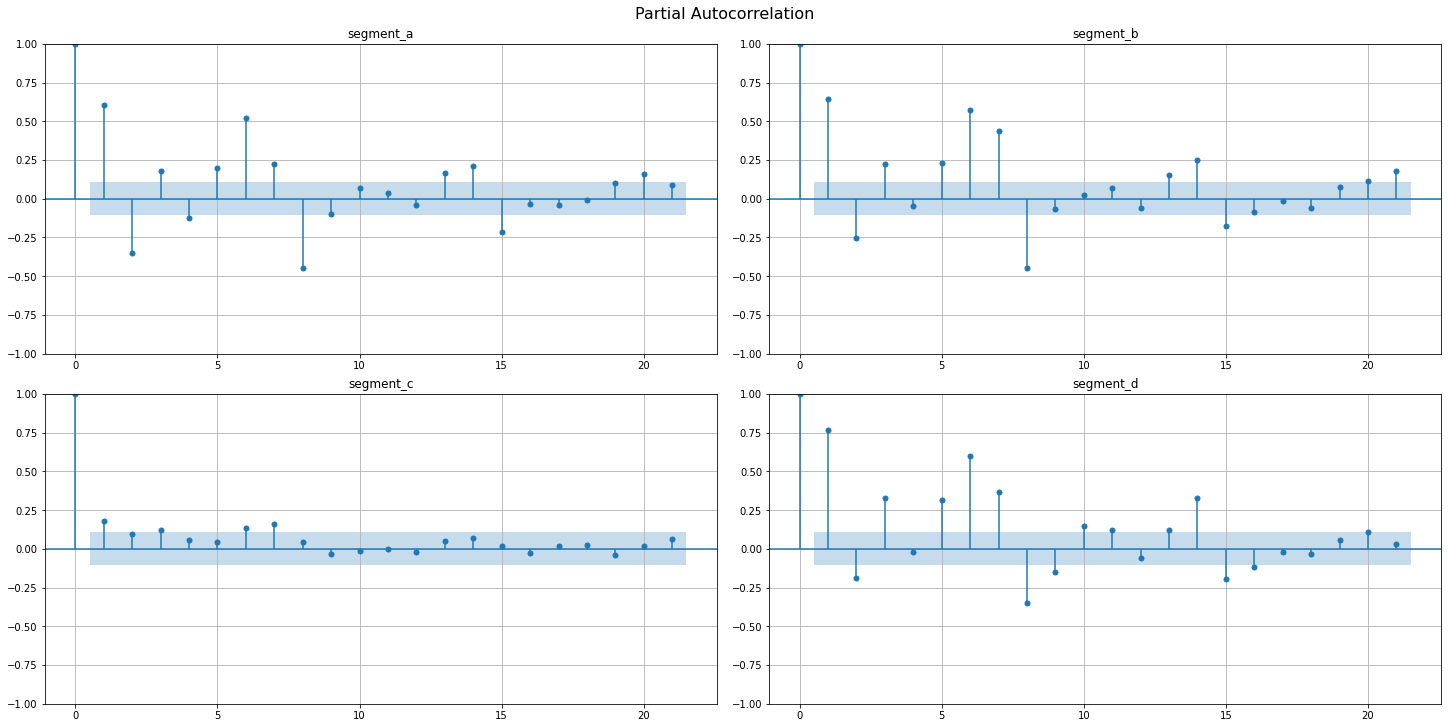
Partial autocorrelation function(PAFC) describes the direct relationship between an observation and its lag. The PAFC plot can help to identify the extent of the lag in autoregressive models.
Let’s observe the AFC and PAFC plot for our time series, specifying the maximum number of lags
[39]:
acf_plot(ts, lags=21)
[40]:
acf_plot(ts, lags=21, partial=True)
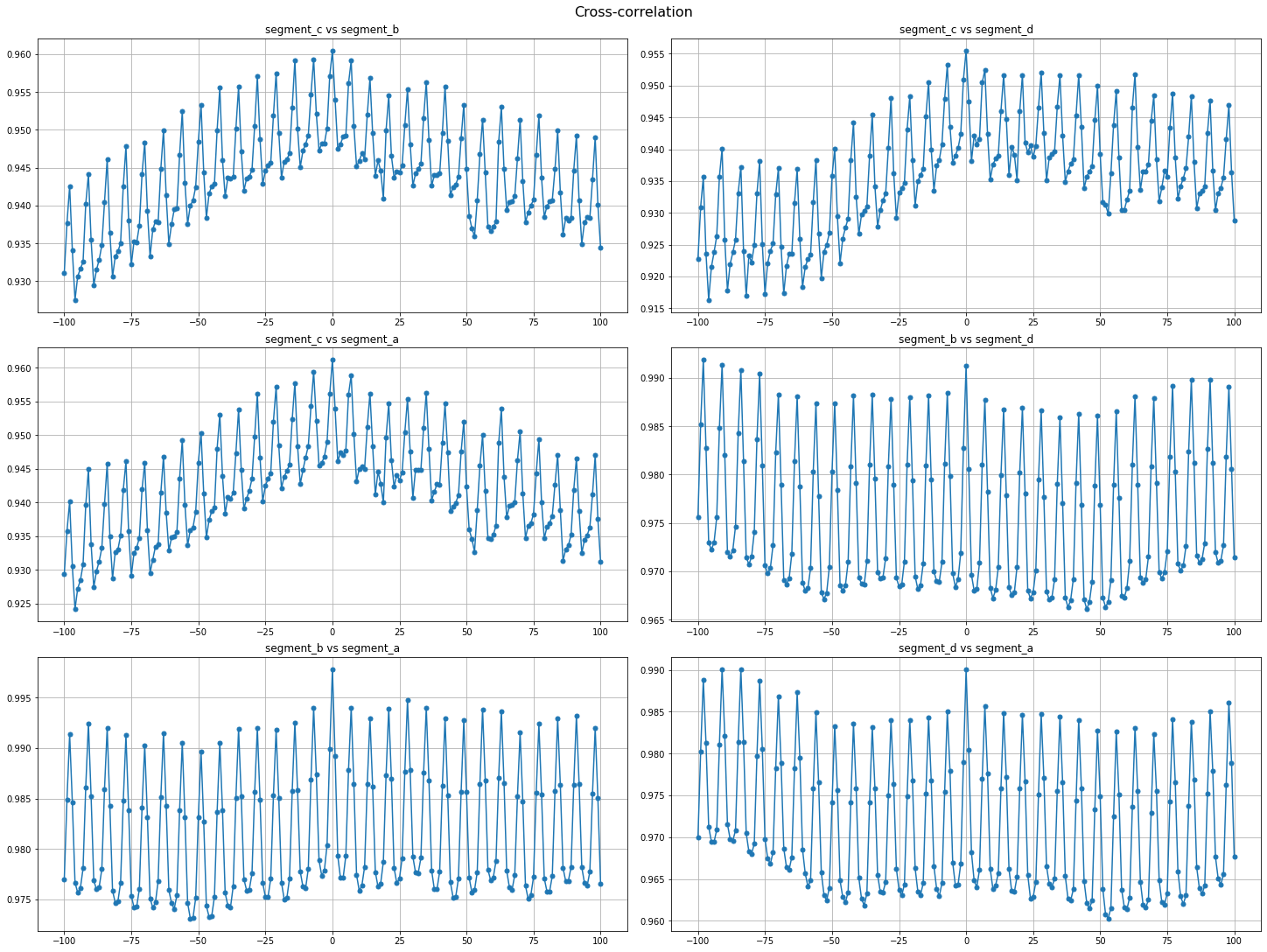
2.3 Cross-correlation¶
Cross-correlation is generally used to compare multiple time series and determine how well they match up with each other and, in particular, at what point the best match occurs. The closer the cross-correlation value is to \(1\), the more closely the sets are identical.
Let’s plot the cross-correlation for all pairs of time series in our dataset
[13]:
cross_corr_plot(ts, maxlags=100)
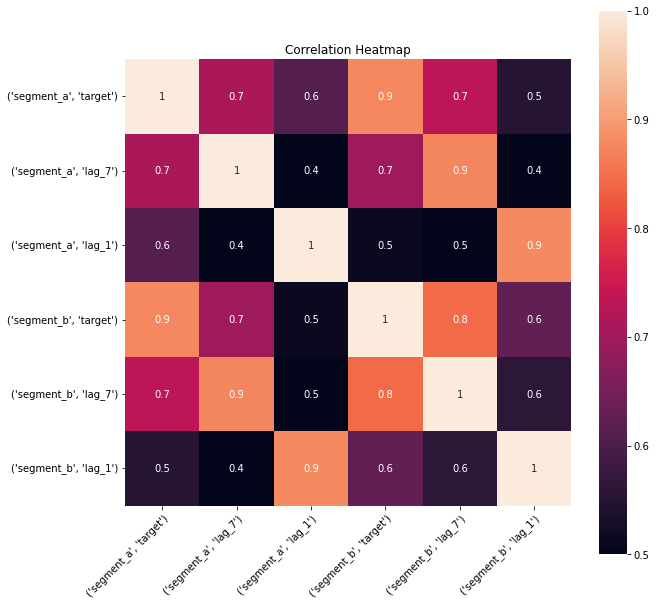
2.4 Correlation heatmap¶
Correlation heatmap is a visualization of pairwise correlation matrix between timeseries in a dataset. It is a simple visual tool which you may use to determine the correlated timeseries in your dataset.
Let’s take a look at the correlation heatmap, adding lags columns to the dataset to catch the series that are correlated but with some shift.
[14]:
from etna.transforms import LagTransform
[15]:
lags = LagTransform(in_column="target", lags=[1, 7], out_column="lag")
ts.fit_transform([lags])
[16]:
plot_correlation_matrix(ts, segments=["segment_a", "segment_b"], method="spearman", vmin=0.5, vmax=1)
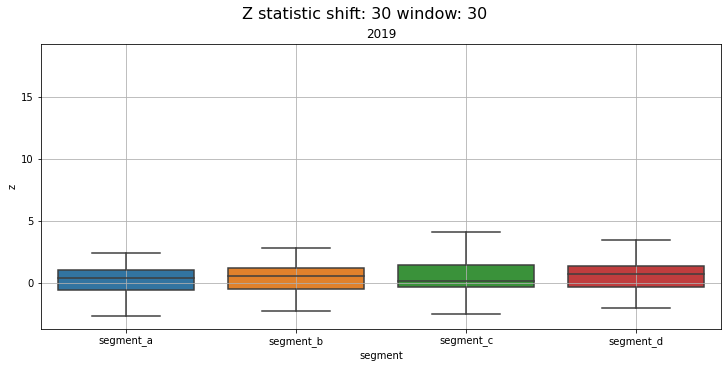
2.5 Distribution¶
Distribution of z-values grouped by segments and time frequency. Using this plot, you can monitor the data drifts over time.
Let’s compare the distributions over each year in the dataset
[17]:
distribution_plot(ts, freq="1Y")
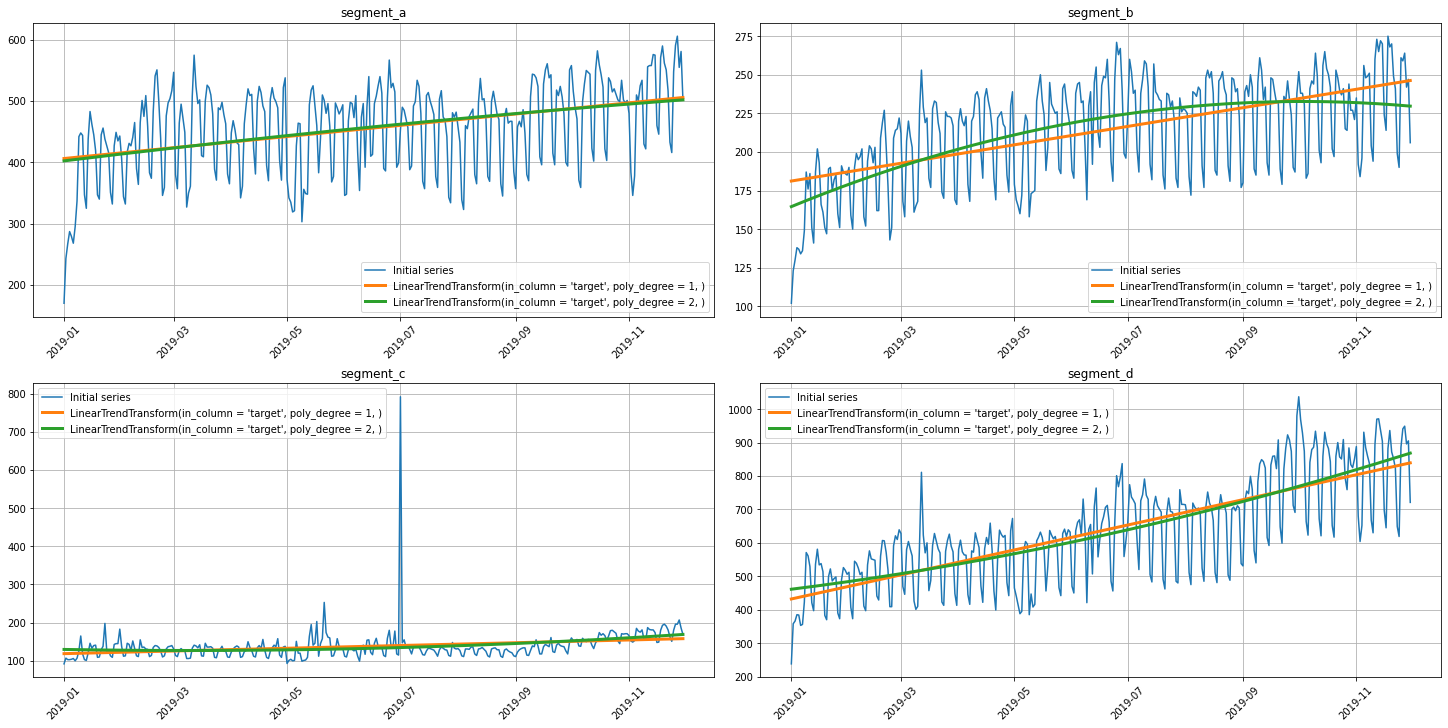
2.6 Trend¶
Time series have such an important characteristic as a trend. Using plot_trend, you can visualize the trend for each segment and select the appropriate model to describe it.
For example, let’s build a linear and parabolic trend.
[18]:
from etna.analysis import plot_trend
from etna.transforms import LinearTrendTransform
[19]:
trends = [
LinearTrendTransform(in_column="target", poly_degree=1),
LinearTrendTransform(in_column="target", poly_degree=2),
]
[20]:
plot_trend(ts, trend_transform=trends)
2.7 Seasonality¶
Our library provide several methods for seasonality analysis.
[21]:
from etna.analysis import plot_periodogram, stl_plot, seasonal_plot
The first one, plot_periodogram visualize the amplitudes of the fourier components inside the period. This method might be useful determine the order parameter in FourierTransform . The rule of thumb is to set the order as the last significant pick of amplitude.
[22]:
plot_periodogram(ts, period=365.2425, amplitude_aggregation_mode="per-segment", xticks=[1, 2, 4, 6, 12, 26, 52, 104])
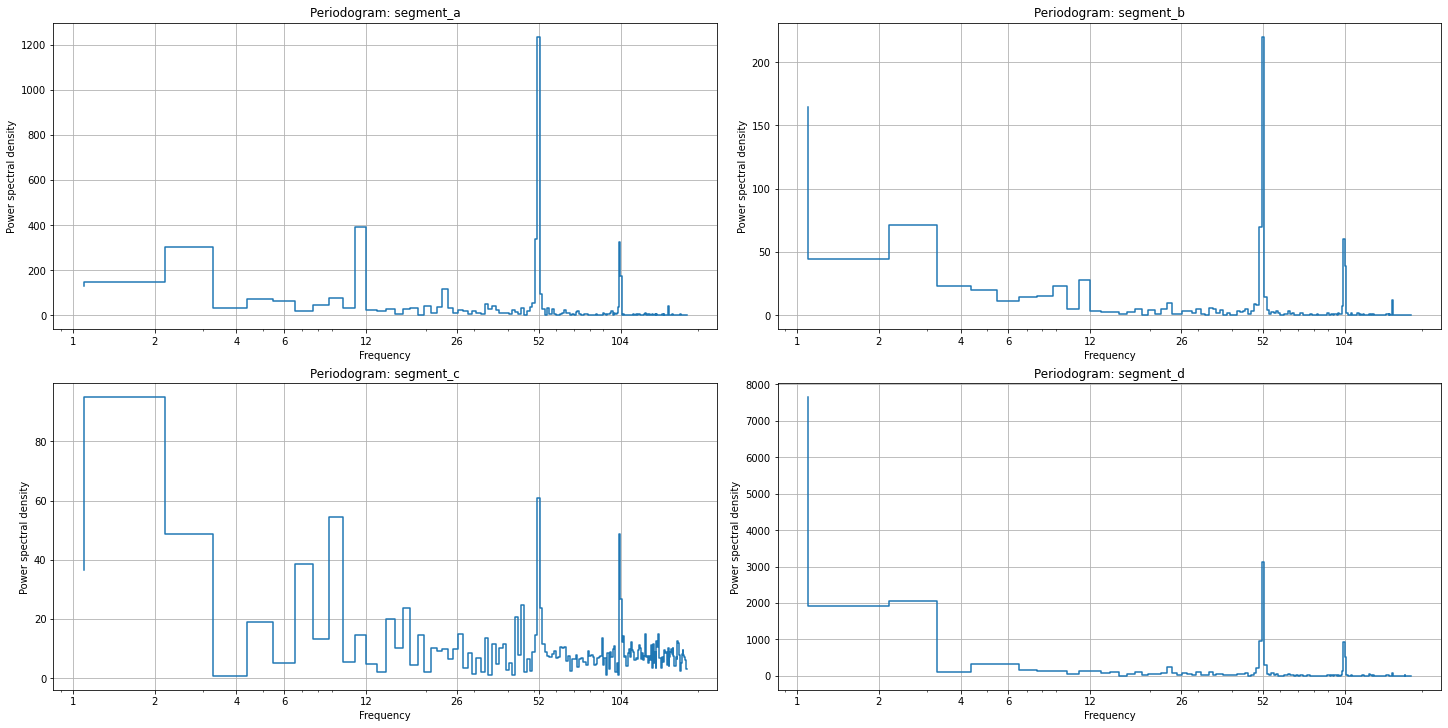
The second one, pics in the periodogram also shows the existence of corresponding seasonality, i.e. pick near x=52 shows the weekly seasonality (52 times a year).
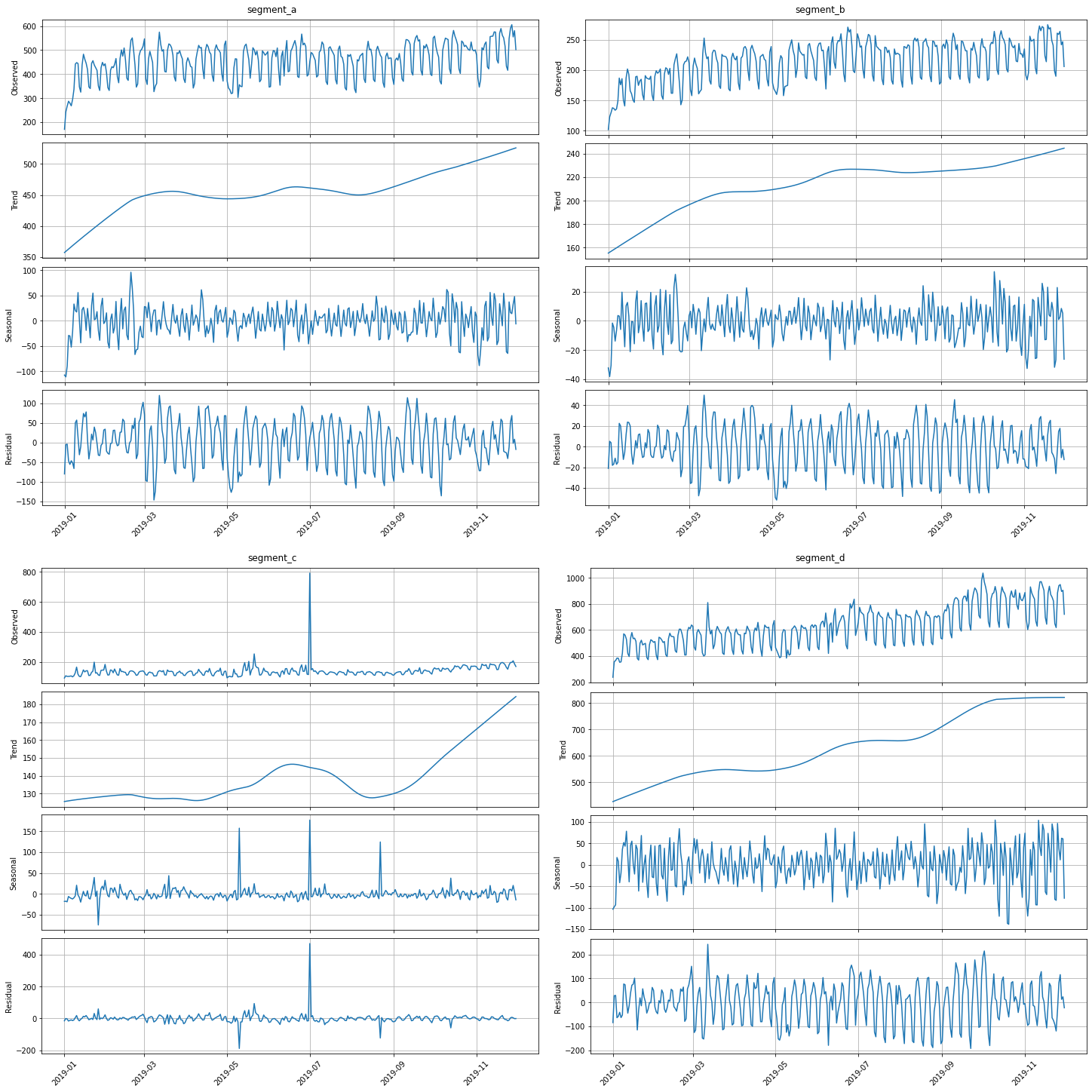
stl_plot is a visualization of the corresponding decomposition
[23]:
stl_plot(ts=ts, period=52)
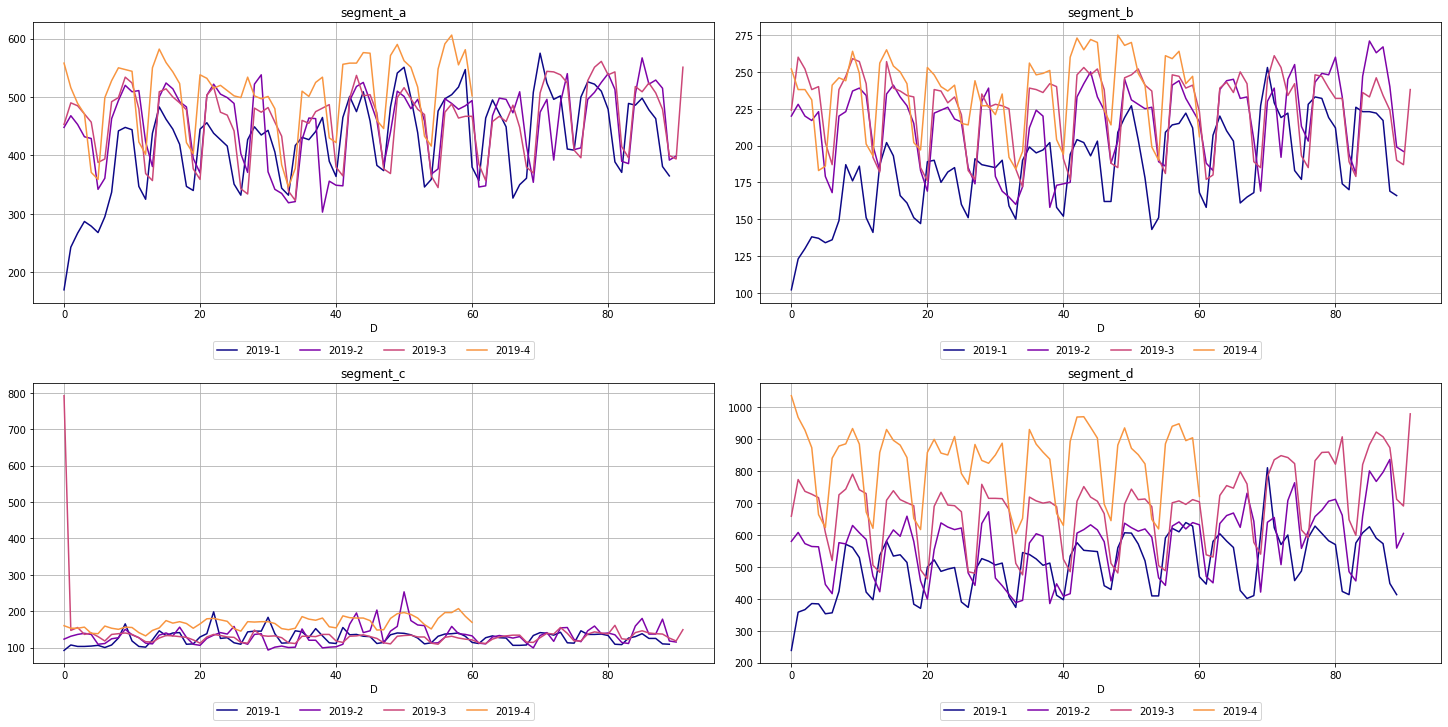
The third one, seasonal_plot helps to visualize the a specific period of seasonality (hour, day, week, month, quarter, year). A seasonal_plot allows the underlying seasonal pattern to be seen more clearly, and is especially useful in identifying periods in which the pattern changes
[24]:
seasonal_plot(ts=ts, cycle="quarter")
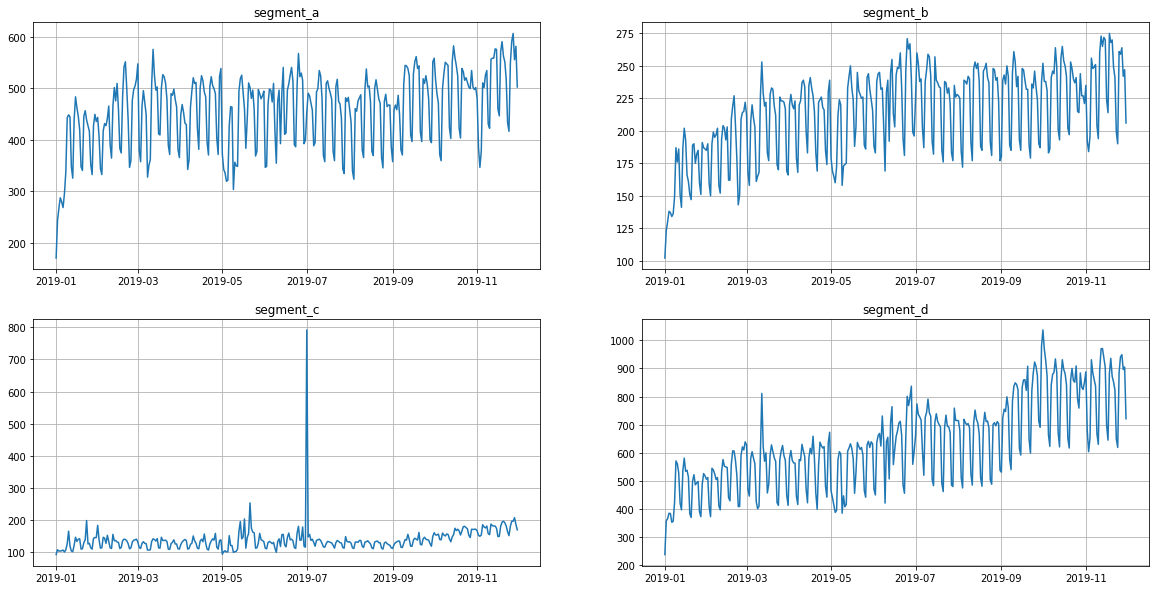
3. Outliers¶
Visually, all the time series contain outliers - abnormal spikes on the plot. Their presence might cause the reduce in predictions quality.
[25]:
ts.plot()
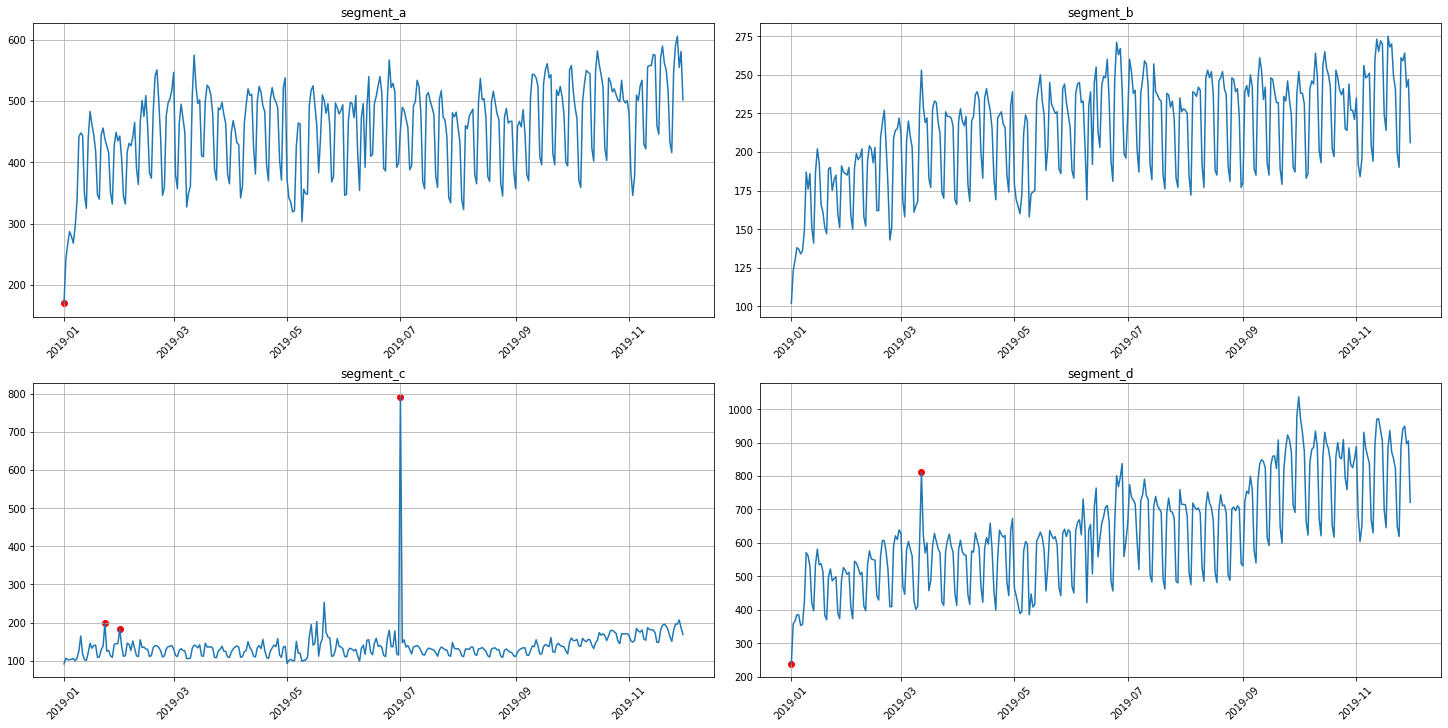
In our library, we provide two methods for outliers detection. In addition, you can easily visualize the detected outliers using plot_anomalies
[26]:
from etna.analysis.outliers import get_anomalies_median, get_anomalies_density
from etna.analysis import plot_anomalies
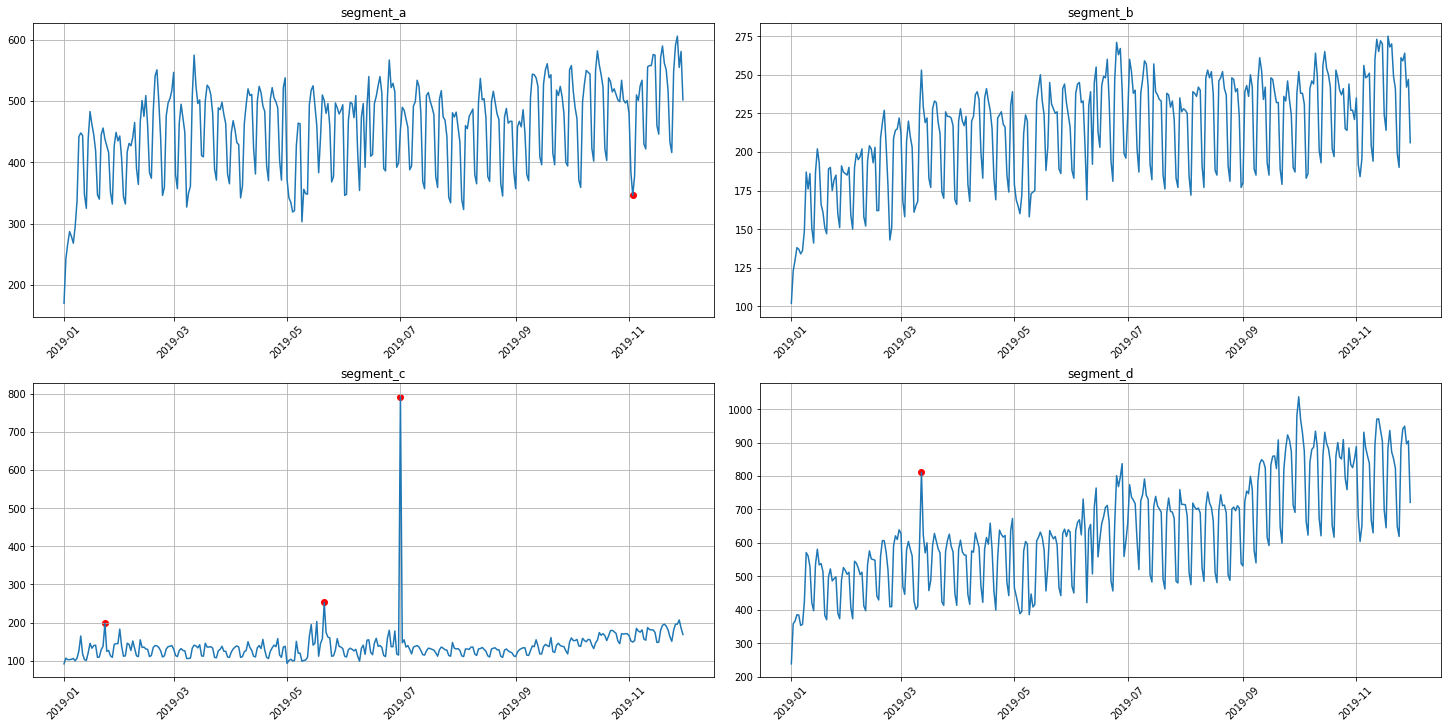
3.1 Median method¶
To obtain the point outliers using the median method we need to specify the window for fitting the median model.
[27]:
anomaly_dict = get_anomalies_median(ts, window_size=100)
plot_anomalies(ts, anomaly_dict)
3.2 Density method¶
It is a distance-based method for outliers detection. Don’t rely on default parameters)
[28]:
anomaly_dict = get_anomalies_density(ts)
plot_anomalies(ts, anomaly_dict)
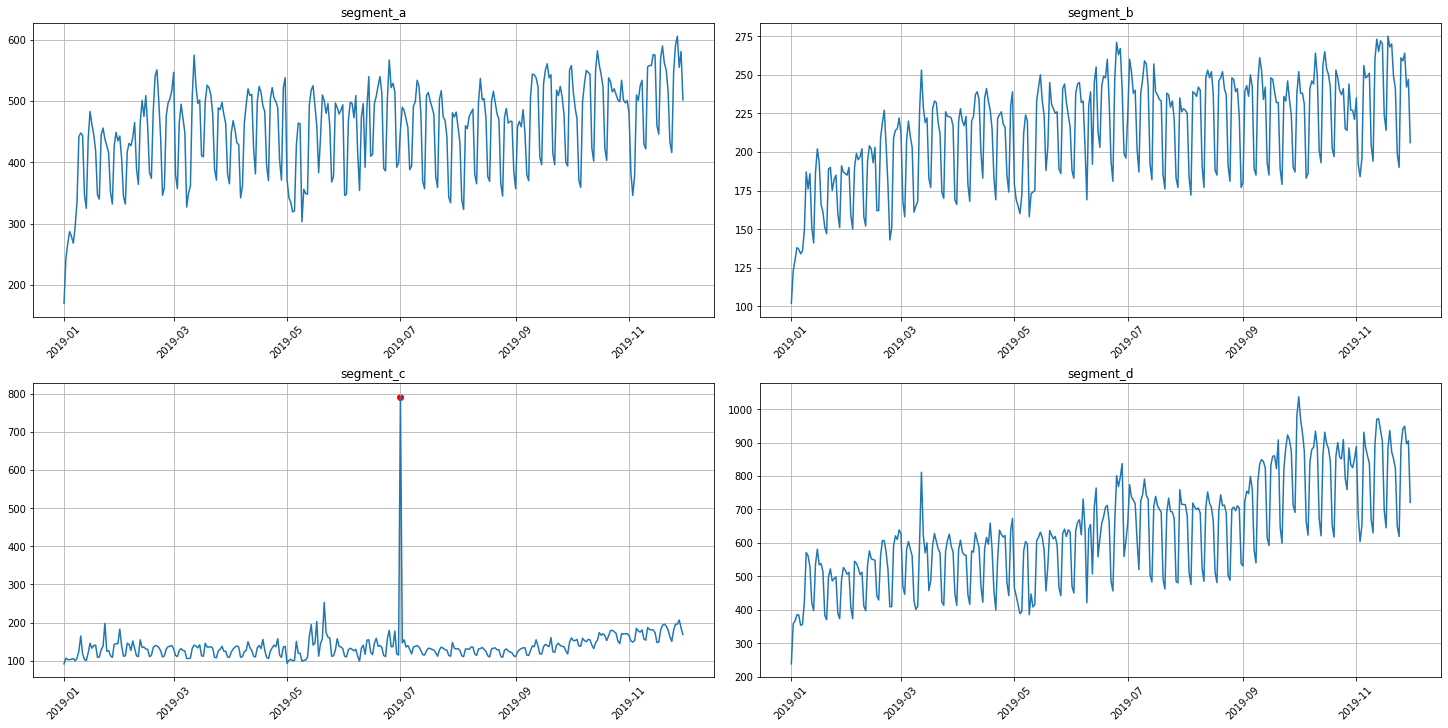
The best practice here is to specify the method parameters for your data
[29]:
anomaly_dict = get_anomalies_density(ts, window_size=18, distance_coef=1, n_neighbors=4)
plot_anomalies(ts, anomaly_dict)
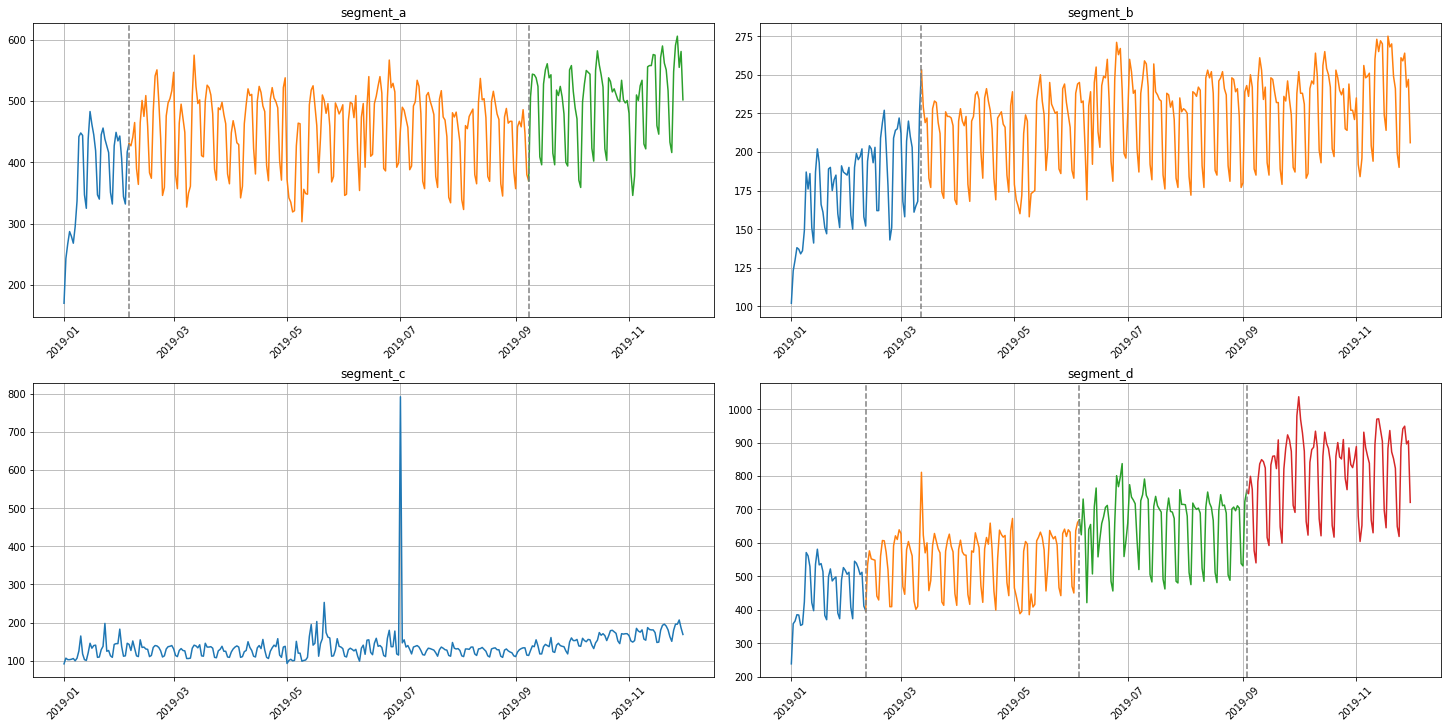
4. Change Points¶
Sometimes the series contains trend changes in history. Identification and processing of trends taking into account changes can help in forecasting
In our library we provide 2 methods for visualization change points
[30]:
from etna.analysis import plot_time_series_with_change_points, plot_change_points_interactive
from etna.analysis import find_change_points
from ruptures.detection import Binseg
[31]:
change_points = find_change_points(ts=ts, in_column="target", change_point_model=Binseg(), pen=1e5)
plot_time_series_with_change_points(ts=ts, change_points=change_points)
For better initialization parameters there are exist interactive EDA method.
In some cases there might be troubles with this visualisation in Jupyter notebook, try to use !jupyter nbextension enable --py widgetsnbextension
[32]:
params_bounds = {"n_bkps": [0, 8, 2], "min_size": [1, 10, 3]}
plot_change_points_interactive(
ts=ts,
change_point_model=Binseg,
model="l2",
params_bounds=params_bounds,
model_params=["min_size"],
predict_params=["n_bkps"],
figsize=(20, 10),
)
That’s all for this notebook. More features for time series analysis you can find in our documentation.