Classification notebook¶
![]()
This notebook contains the simple examples of timeseries classification using ETNA library.
Table of Contents
Classification¶
Task formulation: Given the set of time series \(\{x_i\}_{i=1}^{N}\) and corresponding labels \(\{y_i\}_{i=1}^{N}\) we need to find a classifier that can learn the relationship between time series and label and accurately predict the label of new series.
Our library introduces tools for binary time series classification in experimental format. This implies that the architecture and the API of the objects from etna.experimental module might face changes in the future. To use this module, you need to install the corresponding dependencies.
[1]:
#!pip install "etna[classification]" -q
Load Dataset¶
Consider the example FordA dataset from UCR archive. Dataset consists of engine noise measurements and the problem is to diagnose whether a certain symptom exists in the engine. The comprehensive description of FordA dataset can be found here.
It is possible to load the dataset using fetch_ucr_dataset function from `pyts library <https://pyts.readthedocs.io/en/stable/index.html>`__, but let’s do it manually.
[2]:
!curl "https://timeseriesclassification.com/aeon-toolkit/FordA.zip" -o data/ford_a.zip
!unzip -q data/ford_a.zip -d data/ford_a
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 34.6M 100 34.6M 0 0 3062k 0 0:00:11 0:00:11 --:--:-- 3532k
[3]:
import pathlib
import numpy as np
[4]:
def load_ford_a(path: pathlib.Path, dataset_name: str):
train_path = path / (dataset_name + "_TRAIN.txt")
test_path = path / (dataset_name + "_TEST.txt")
data_train = np.genfromtxt(train_path)
data_test = np.genfromtxt(test_path)
X_train, y_train = data_train[:, 1:], data_train[:, 0]
X_test, y_test = data_test[:, 1:], data_test[:, 0]
y_train = y_train.astype("int64")
y_test = y_test.astype("int64")
return X_train, X_test, y_train, y_test
[5]:
X_train, X_test, y_train, y_test = load_ford_a(pathlib.Path("data") / "ford_a", "FordA")
y_train[y_train == -1], y_test[y_test == -1] = 0, 0 # transform labels to 0,1
[6]:
X_train.shape, X_test.shape, y_train.shape, y_test.shape
[6]:
((3601, 500), (1320, 500), (3601,), (1320,))
Let’s visualize a sample from each class.
[7]:
import matplotlib.pyplot as plt
[8]:
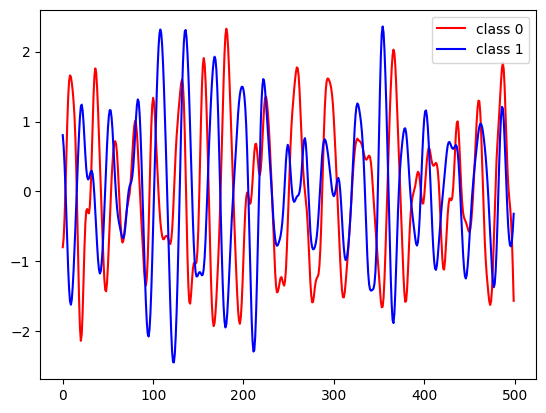
for c in [0, 1]:
class_samples = X_train[y_train == c]
plt.plot(class_samples[0], label="class " + str(c), c=["r", "b"][c])
plt.legend(loc="best");
Feature extraction¶
Raw time series values are usually not the best features for the classifier. The length of the series is usually much greater than the number of samples in the dataset, in which case classifiers will perform poorly. There are special techniques to extract more informative features from the time series, you can find a comprehensive review of them in this paper.
In our library we offer two methods for feature extraction that can work with the time series of different lengths: 1. TSFreshFeatureExtractor — extract features using extract_features method form tsfresh.
[9]:
from etna.experimental.classification.feature_extraction import TSFreshFeatureExtractor
Constructor expects parameters of extract_features method, see the full list here. It also has parameter fill_na_value that defines the value for filling the possible NaNs in the generated features.
[10]:
from etna.experimental.classification.feature_extraction import TSFreshFeatureExtractor
from tsfresh.feature_extraction.settings import MinimalFCParameters
from tsfresh import extract_features
[11]:
tsfresh_feature_extractor = TSFreshFeatureExtractor(default_fc_parameters=MinimalFCParameters(), fill_na_value=-100)
WEASELFeatureExtractor— extract features using the WEASEL algorithm, see the original paper.
[12]:
from etna.experimental.classification.feature_extraction import WEASELFeatureExtractor
[13]:
weasel_feature_extractor = feature_extractor = WEASELFeatureExtractor(
padding_value=-10,
word_size=4,
n_bins=4,
window_sizes=[0.2, 0.3, 0.5, 0.7, 0.9],
window_steps=[0.1, 0.15, 0.25, 0.35, 0.45],
chi2_threshold=2,
)
Performance evaluation¶
To evaluate the performance of our feature extraction methods, we will use masked_crossval_score method of TimeSeriesBinaryClassifier.
[14]:
from etna.experimental.classification import TimeSeriesBinaryClassifier
from sklearn.linear_model import LogisticRegression
Firstly, we need to create the instance of TimeSeriesBinaryClassifier, which requires setting the feature extractor and the classification model with sklearn interface.
[15]:
model = LogisticRegression(max_iter=1000)
clf = TimeSeriesBinaryClassifier(feature_extractor=tsfresh_feature_extractor, classifier=model)
Then we need to prepare the fold masks
[16]:
from sklearn.model_selection import KFold
[17]:
mask = np.zeros(len(X_train))
for fold_idx, (train_index, test_index) in enumerate(KFold(n_splits=5).split(X_train)):
mask[test_index] = fold_idx
Then we can run the cross validation and evaluate the performance on 5 folds.
[18]:
metrics = clf.masked_crossval_score(x=X_train, y=y_train, mask=mask)
Feature Extraction: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2880/2880 [00:01<00:00, 2831.47it/s]
Feature Extraction: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 721/721 [00:00<00:00, 2993.07it/s]
Feature Extraction: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2881/2881 [00:00<00:00, 2994.12it/s]
Feature Extraction: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 720/720 [00:00<00:00, 3219.79it/s]
Feature Extraction: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2881/2881 [00:00<00:00, 3068.71it/s]
Feature Extraction: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 720/720 [00:00<00:00, 3063.48it/s]
Feature Extraction: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2881/2881 [00:01<00:00, 2821.06it/s]
Feature Extraction: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 720/720 [00:00<00:00, 2936.95it/s]
Feature Extraction: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2881/2881 [00:00<00:00, 2931.89it/s]
Feature Extraction: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 720/720 [00:00<00:00, 2979.54it/s]
The returned metrics dict contains the set of standard classification metrics for each fold:
[19]:
metrics
[19]:
{'precision': [0.5383522727272727,
0.5160048049745619,
0.5422891046203586,
0.48479549208199746,
0.5564688579909953],
'recall': [0.531589156237011,
0.5139824524851263,
0.538684876779783,
0.4855088120003704,
0.5484257847863261],
'fscore': [0.511929226858391,
0.497349709114415,
0.5324451810300866,
0.4796875,
0.5365782570679103],
'AUC': [0.5555427269508459,
0.5453465132609517,
0.5570033834266291,
0.5186734158461681,
0.5629105765287568]}
[20]:
{metric: np.mean(values) for metric, values in metrics.items()}
[20]:
{'precision': 0.5275821064790372,
'recall': 0.5236382164577233,
'fscore': 0.5115979748141605,
'AUC': 0.5478953232026702}
This feature extraction method shows quite poor quality on this dataset, let’s try out the second one.
[21]:
clf = TimeSeriesBinaryClassifier(feature_extractor=weasel_feature_extractor, classifier=model)
metrics = clf.masked_crossval_score(x=X_train, y=y_train, mask=mask)
[22]:
metrics
[22]:
{'precision': [0.8489879944589811,
0.8723519197376037,
0.8526994807058697,
0.8640069169960474,
0.8791666666666667],
'recall': [0.8490470912421682,
0.8723059471722574,
0.8539010057371147,
0.8638383900737677,
0.8802257832388056],
'fscore': [0.848819918551392,
0.8722212362749713,
0.8526401964797381,
0.863862627821725,
0.8790824629033722],
'AUC': [0.9314875536877107,
0.945698389548657,
0.9299313249560619,
0.9476758541930307,
0.9500847267465704]}
[23]:
{metric: np.mean(values) for metric, values in metrics.items()}
[23]:
{'precision': 0.8634425957130338,
'recall': 0.8638636434928226,
'fscore': 0.8633252884062397,
'AUC': 0.9409755698264062}
As you can see, the feature extraction performance strongly depends on the task domain, so it is a good practice to benchmark several methods on your task.
Predictability analysis¶
Task formulation: Given the set of time series \(\{x_i\}_{i=1}^{N}\) we need to define whether each of the series can be forecasted with some quality threshold.
This is the extension of the classification task, which helps you to perform some kind of pre-validation on your dataset. This might help to identify the “bad” segments, which should be processed separately.
You can train the PredictabilityAnalyzer on your own, however it requires using the dataset consists of the best possible scores for the segments, which might be hard to collect. Therefore, we pretrained several instances of the analyzer on the datasets with H, D and W frequencies.
Load Dataset¶
To demonstrate the usage of this tool, we will use M4 dataset.
[24]:
import pandas as pd
from etna.datasets import TSDataset
from tqdm.notebook import tqdm
[25]:
!curl "https://raw.githubusercontent.com/Mcompetitions/M4-methods/master/Dataset/Train/Daily-train.csv" -o data/m4.csv
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 91.3M 100 91.3M 0 0 3773k 0 0:00:24 0:00:24 --:--:-- 2034k 0 0 4745k 0 0:00:19 0:00:14 0:00:05 3752k
[26]:
df_raw = pd.read_csv("data/m4.csv")
[27]:
dfs = []
for i in tqdm(range(len(df_raw))):
segment_name = df_raw.iloc[i, 0]
segment_values = df_raw.iloc[i, 1:].dropna().astype(float).values
segment_len = len(segment_values)
timestamps = pd.date_range(
start=pd.to_datetime("2022-11-04") - pd.to_timedelta("1d") * (segment_len - 1), end="2022-11-04"
)
df_segment = pd.DataFrame({"target": segment_values, "segment": segment_name, "timestamp": timestamps})
dfs.append(df_segment)
[28]:
df = pd.concat(dfs)
df = TSDataset.to_dataset(df)
ts = TSDataset(df=df, freq="D")
Let’s visualize several random segments from the dataset
[29]:
print("Number of segments:", len(ts.segments))
ts.plot(n_segments=10)
Number of segments: 4227
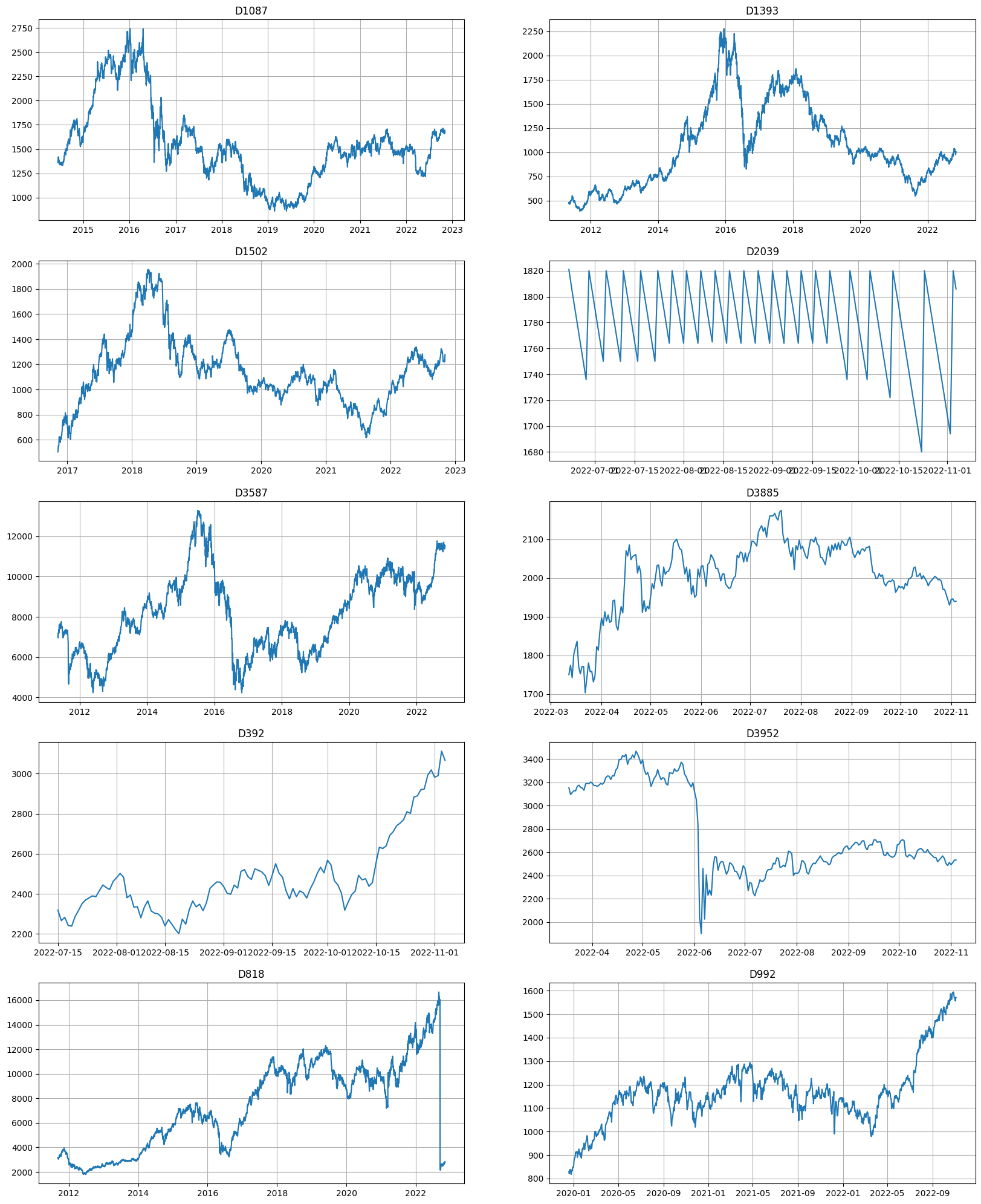
Dataset consists of 4k segments of 1-4 years length. As the plot suggests, the behavior of the segments are different across the dataset, and it might be hard to predict all of them accurately. Let’s try to evaluate the SMAPE on the backtest using some baseline model.
[30]:
from etna.pipeline import Pipeline
from etna.models import NaiveModel
from etna.metrics import SMAPE
[31]:
pipeline = Pipeline(model=NaiveModel(), transforms=[], horizon=30)
It takes about 2 minutes even for naive model to evaluate the performance on this dataset, imagine how long it takes for more complex one.
[32]:
metrics, _, _ = pipeline.backtest(ts, metrics=[SMAPE()], n_folds=3, aggregate_metrics=False)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 1.4s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 2.9s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 4.5s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 4.5s finished
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
/Users/d.a.binin/Documents/tasks/etna-github/etna/datasets/tsdataset.py:279: FutureWarning: Argument `closed` is deprecated in favor of `inclusive`.
future_dates = pd.date_range(
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 3.5s remaining: 0.0s
/Users/d.a.binin/Documents/tasks/etna-github/etna/datasets/tsdataset.py:279: FutureWarning: Argument `closed` is deprecated in favor of `inclusive`.
future_dates = pd.date_range(
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 7.1s remaining: 0.0s
/Users/d.a.binin/Documents/tasks/etna-github/etna/datasets/tsdataset.py:279: FutureWarning: Argument `closed` is deprecated in favor of `inclusive`.
future_dates = pd.date_range(
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 10.4s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 10.5s finished
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 3.8s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 7.7s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 11.4s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 11.5s finished
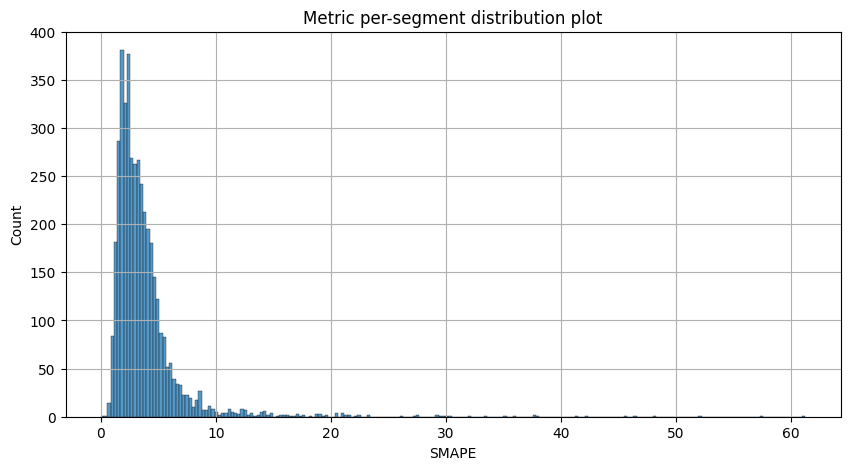
Let’s visualize the resulting metrics
[33]:
from etna.analysis import metric_per_segment_distribution_plot, plot_metric_per_segment
[34]:
metric_per_segment_distribution_plot(metrics_df=metrics, metric_name="SMAPE", per_fold_aggregation_mode="mean")
[35]:
plot_metric_per_segment(metrics_df=metrics, metric_name="SMAPE", top_k=20)
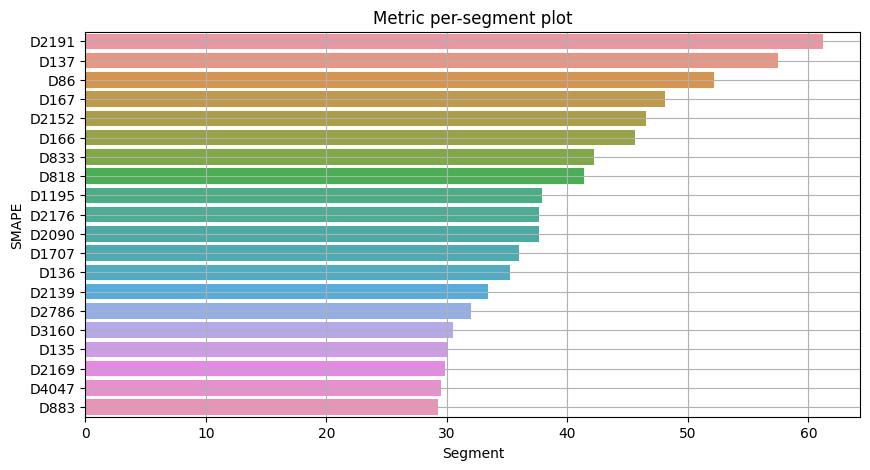
Most of the segments can be forecasted with SMAPE less than 10, however there is a list of segments with SMAPE greater than 20 which we want to catch and analyze separately.
[36]:
agg_metrics = metrics.groupby("segment").mean().reset_index()
bad_segment_metrics = agg_metrics[agg_metrics["SMAPE"] >= 20]
print(f"Number of bad segments: {len(bad_segment_metrics)}")
Number of bad segments: 42
Load pretrained analyzer¶
[37]:
from etna.experimental.classification import PredictabilityAnalyzer
Let’s look at the list of available analyzers
[38]:
PredictabilityAnalyzer.get_available_models()
[38]:
['weasel', 'tsfresh', 'tsfresh_min']
Pertained analyzer can be loaded from the public s3 bucket by it’s name and dataset frequency
[39]:
PredictabilityAnalyzer.download_model(model_name="weasel", dataset_freq="D", path="weasel_analyzer.pickle")
Once we loaded the analyzer, we can create an instance of it
[40]:
weasel_analyzer = PredictabilityAnalyzer.load("weasel_analyzer.pickle")
Analyze segments predictability¶
Now we can analyze the dataset for predictability, which might be done the two ways.
[41]:
def metrics_for_bad_segments(predictability):
bad_segments = [segment for segment in predictability if predictability[segment] == 1]
metrics_for_bad_segments = agg_metrics[agg_metrics["segment"].isin(bad_segments)].sort_values(
"SMAPE", ascending=False
)
print(f"Number of bad segments: {len(metrics_for_bad_segments)}")
return metrics_for_bad_segments
The short way: using
analyze_predictabilitymethod.
[42]:
%%time
predictability = weasel_analyzer.analyze_predictability(ts)
CPU times: user 12.3 s, sys: 1.03 s, total: 13.3 s
Wall time: 13.4 s
[43]:
metrics = metrics_for_bad_segments(predictability)
Number of bad segments: 133
The long way: using
predict_probamethod. This is more flexible as you can choose the threshold for predictability score.
[44]:
%%time
series = weasel_analyzer.get_series_from_dataset(ts)
predictability_score = weasel_analyzer.predict_proba(series)
CPU times: user 14 s, sys: 1.12 s, total: 15.1 s
Wall time: 15.1 s
[45]:
threshold = 0.4
predictability = {segment: int(predictability_score[i] > threshold) for i, segment in enumerate(sorted(ts.segments))}
[46]:
metrics = metrics_for_bad_segments(predictability)
Number of bad segments: 406
Let’s take a look at the segments with the bad metrics:
[47]:
metrics.head(10)
[47]:
| segment | SMAPE | fold_number | |
|---|---|---|---|
| 412 | D137 | 57.452473 | 1.0 |
| 4072 | D86 | 52.144064 | 1.0 |
| 734 | D166 | 45.620776 | 1.0 |
| 3387 | D4047 | 29.501460 | 1.0 |
| 1310 | D2178 | 29.205434 | 1.0 |
| 4061 | D85 | 22.579621 | 1.0 |
| 1205 | D2083 | 22.547771 | 1.0 |
| 3333 | D4 | 20.994039 | 1.0 |
| 357 | D132 | 15.903925 | 1.0 |
| 2778 | D35 | 14.327464 | 1.0 |
[48]:
ts.plot(segments=metrics.head(10)["segment"])
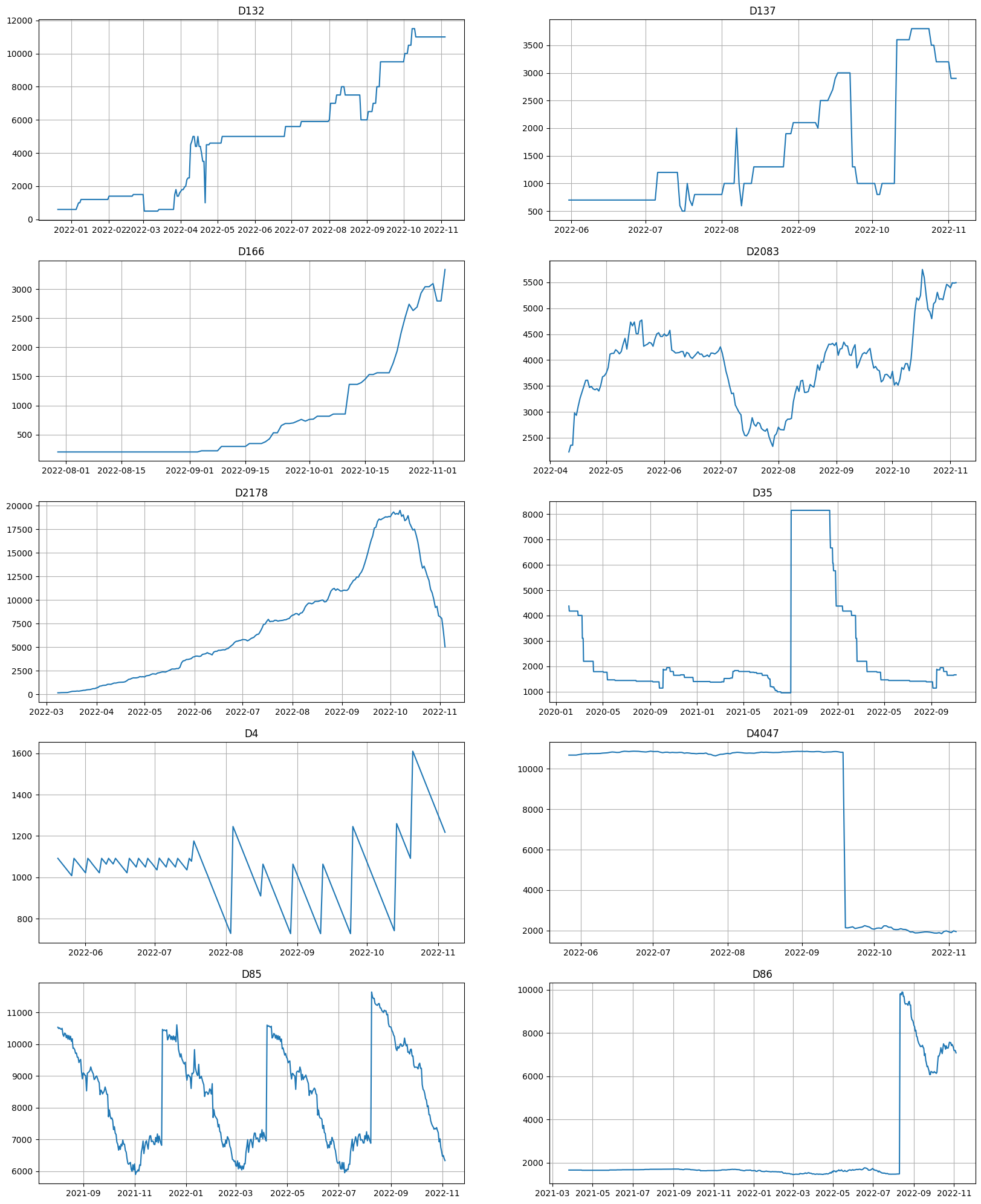
It took only about 15 seconds to analyze the dataset and suggest the set of possible bad segments for weasel-based analyzer, which is much faster than using any baseline pipeline.
However, there might be false-positives in the results.
[49]:
metrics.tail(10)
[49]:
| segment | SMAPE | fold_number | |
|---|---|---|---|
| 1234 | D2109 | 1.387898 | 1.0 |
| 2972 | D3674 | 1.384460 | 1.0 |
| 3706 | D53 | 1.294982 | 1.0 |
| 3534 | D418 | 1.281990 | 1.0 |
| 2167 | D295 | 1.258861 | 1.0 |
| 2457 | D321 | 1.177998 | 1.0 |
| 2446 | D320 | 1.123942 | 1.0 |
| 3242 | D3917 | 1.010831 | 1.0 |
| 346 | D131 | 0.487805 | 1.0 |
| 1348 | D2211 | 0.000000 | 1.0 |
[50]:
ts.plot(segments=metrics.tail(10)["segment"])
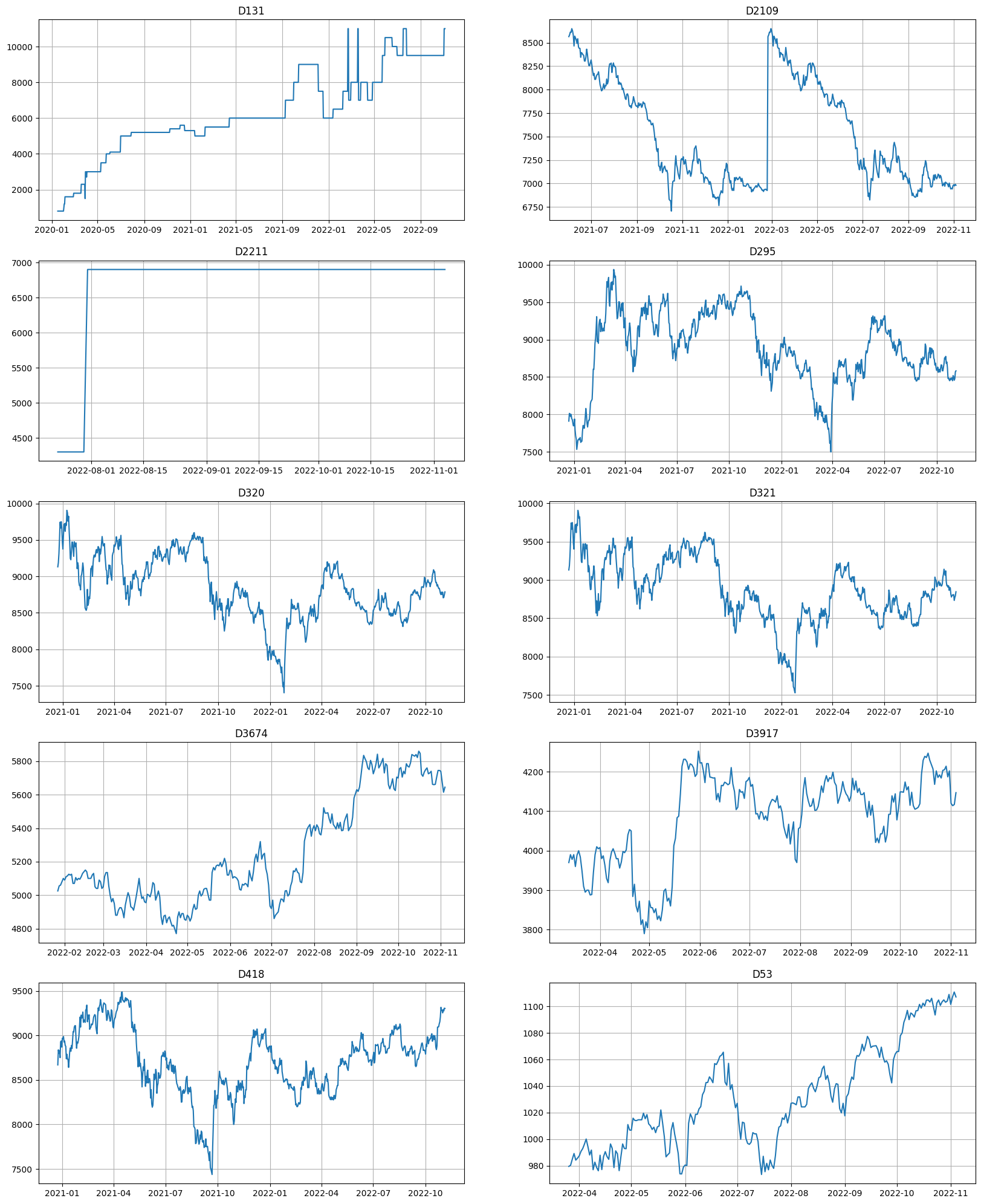
That’s all for this notebook. Remember, that this is an experimental feature, and it might change the interface in the future!